How we protect user data
On this page, we will present a global overview of how we ensure that data sent to our Confidential & transparent AI environment, secure enclaves, remains confidential and how we prove that even admins cannot see users' data.
The concepts section provides a more in-depth explanation of the building blocks we use to ensure user data remains private.
The key to providing end-to-end protection is our secure and transparent systems by design:
-
We design the hardened AI server to be verifiable.
-
We provide a client library to securely consume the AI server.
-
BlindLlama is also optimized for auditability, so that external auditors can completely audit the solution.
At the end of this process, users will know that when using our Python SDK, they will be able to verify that they are talking to a privacy-friendly AI service that will not expose their data.
Server side


1. Hardening the AI server to ensure privacy
We remove all admin/operator access from the AI server, such as SSH access to the machine. This means that once the AI server is running, we are blind to data sent to the service. Because we have no access to data, we can neither see it nor use it for any other purposes. This ensures that no insider threat can impact the production services.
We provide more details about hardened systems in our concepts guide.
2. Proving privacy controls are applied
While other solutions may also claim to put similar controls in place, they usually provide no technical evidence regarding how AI providers will handle or use data. Even where a code base is open-source, users cannot check the server they connect to hosts the application they expect and nothing else.
With BlindLlama, we use secure hardware, Trusted Platform Modules (TPMs), to create a cryptographic proof file to show that the expected hardened server really is deployed in our backend. Before sending any data, end users verify this proof file to make sure they are talking to a privacy-preserving AI infrastructure using our client-side SDK.
We provide more information about TPMs in our concepts guide.
3. Auditing the whole stack
The security and privacy properties we provide are derived from code integrity, i.e. having cryptographic proof that the server we connect to is running the expected BlindLlama open-source code.
But being able to prove we are serving this code is not the full picture.
For users to fully trust us, there needs to be reviews of the codebase for both the Python SDK that performs verification and the BlindLlama server.
Our code is open-source and we encourage the community to review our codebase. We have already had one of our AI deployment solutions, BlindAI, audited by Quarkslab. Community and professional audits help to provide a high level of confidence that our hardened environments implement all the security checks we say they do.
You can find get more details on our implementation of our Confidential & transparent APIs in our whitepaper.
Client side
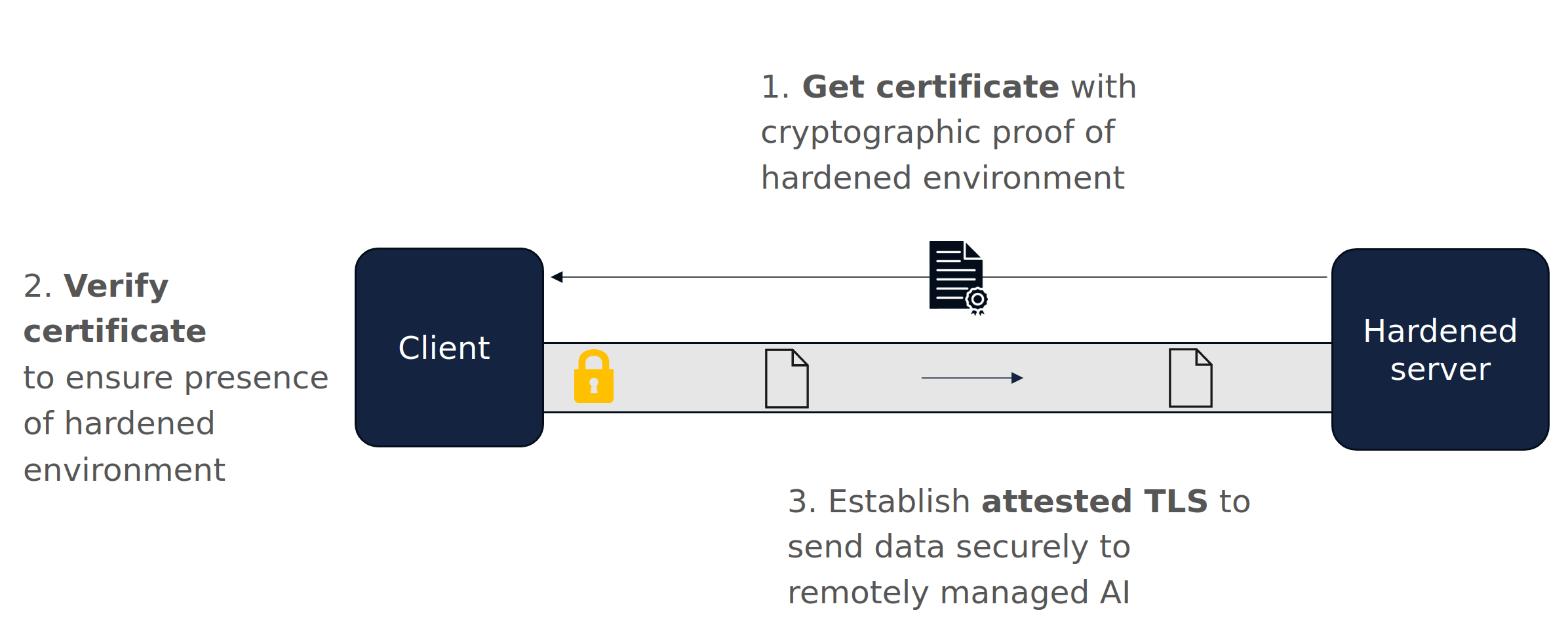
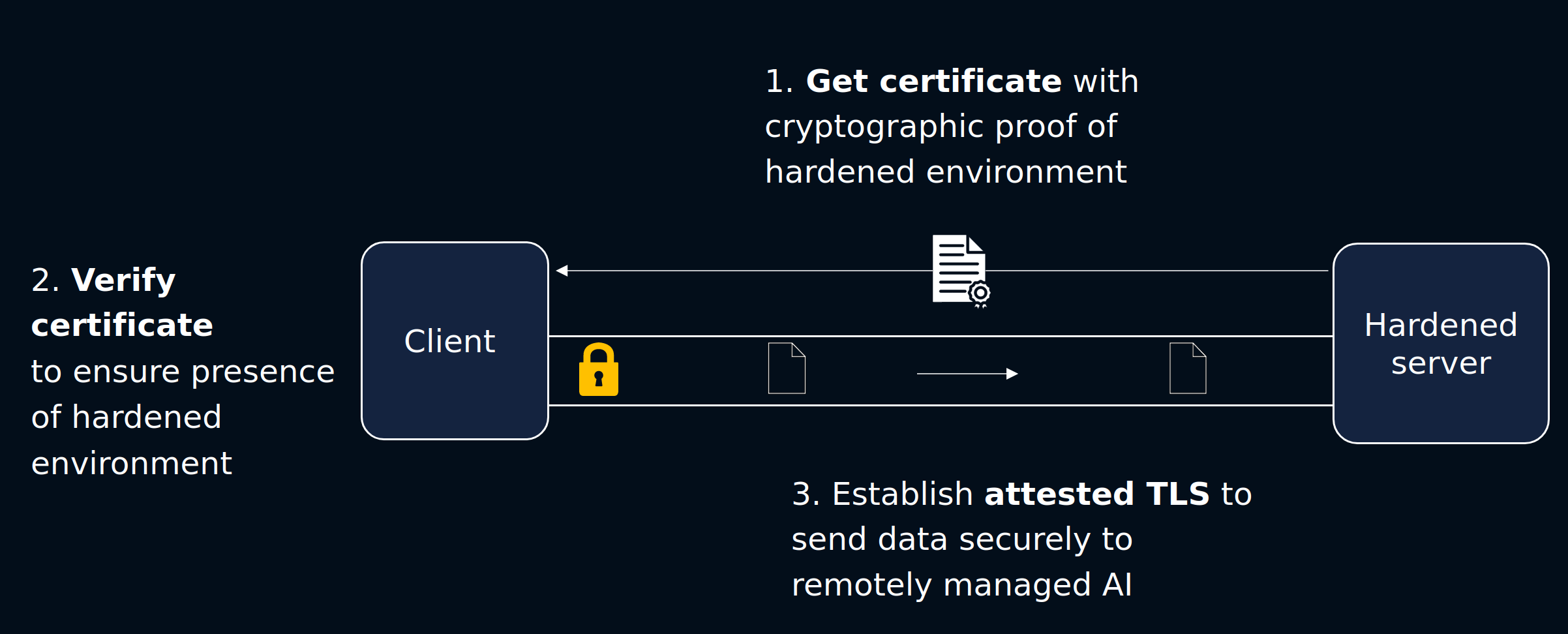
1. Attestation
Before any data can be sent by the end user to the BlindLlama server, the client first verifies that the AI server is running the expected codebase.
This is done by verifying the proof file provided by the server. This file is derived from secure hardware (a TPM) and is used to verify that the expected codebase has been launched.
2. Attested TLS
The server also provides the client with its TLS certificate. This is unique to the server and is used by the client to verify they are talking to the genuine BlindLLama server. If the verification is succesful, the TLS certificate is used to communicate with the hardened AI server using TLS.
The TLS certificate is signed by a private key that lives inside and never leaves the hardened environment.
More information about attestation and attested TLS can be found in our concepts guide.
We also provide a BlindLlama whitepaper for an audience with security expertise which covers the architecture and security features behind BlindLLama in greater detail. You can read or download the whitepaper here!